
Last time I talked about the ‘easy’ consonants found in Proto-Indo-European. Sounds whose pronunciation isn’t really a problem, either in terms of reconstruction or for modern English speakers to get a handle on. The next couple of posts will focus on a couple of more complicated, and sometimes controversial, issues in the sounds of PIE, as we try and figure out what an unwritten language spoken more than 5000 years ago sounded like. Today’s topic is a classic one, the k- and g-type sounds (to keep things from getting out of hand, I’ll mostly focus just on the k-type sounds).
(A quick apology before going on. I’ll be spending a couple more posts on PIE sounds after this. I’m not trying to cover all of PIE phonology, not by a long shot, but I do want to hit most of the ‘big issues’. I also think that if we’re going to talk about the history of English, we should be in a position where I can give a PIE word as a starting point for later developments, and you have at least a basic idea of how to pronounce it. This does mean we’ll move at a slightly slower pace for a bit in this series, lingering on PIE, as a background to everything that will come later.)
Let’s get into this by taking a look at the word raw. If we follow the written records of English back we find the earliest examples of this word, from Old English, spelled with an h- in front: hrēaw. This wasn’t just a funny quirk of spelling, but a real h sound, a voiceless fricative. By Grimm’s Law, we expect that h in Old English (and other old Germanic languages) comes from an older *k, more or less the same way that f comes from *p.
 The Blues Brothers sing 'Rawhide'.
The Blues Brothers sing 'Rawhide'.
If we look at other Indo-European languages, we do in fact find k sounds, just like we expect. Ancient Greek has a noun related to raw, kréas ‘flesh’. Sanskrit also obliges, with kravíṣ ‘gore’. Latin has cruor ‘blood’ – with a c rather than k, but what matters here is sound, not spelling. All of this leads to a straightforward reconstruction of a PIE sound *k: the Greek and Sanskrit forms come from a noun *krewh₂s ‘gore, raw flesh’ (with one of those strange ‘laryngeals’ that we’ll get to later on), and raw is a related derivative. This *k is what we call a velar stop (the soft area at the back of the top of your mouth is the velum, and this kind of sound is made by stopping the airflow there for a moment as you speak). Velar sounds (or velars, for short) are extremely common among the world’s languages, so finding them in PIE is unsurprising. In fact, it might be a bit odd if they weren’t there.
So far, so good – but things get a little more complicated pretty quickly. Let’s return to our word from the first post of this series, what. This goes back to Old English hwæt, with a sequence of h then w. We might expect that this h also goes back to a *k by Grimm’s Law, and we’d be half right. Actually the sound we reconstruct is not a *k followed by a *w, but a single sound, *kʷ (basically a k and a w pronounced at the same time, or a k with rounded lips). A subtle distinction, but a real one, and these ‘labialized velars’ or labio-velars (labia being the Latin term for ‘lip’) are an important part of PIE phonology. So we have two types of velars for PIE: plain *k and the labio-velar *kʷ (and correspondingly *g and *gʷ, and even *gʰ and *gʷʰ, which I’ll talk about in another post).
 Rounded lips pronounce ships (since p is a labial consonant).
Rounded lips pronounce ships (since p is a labial consonant).
(Sorry, I should have warned you I like atrocious puns.)
The labio-velars are not really difficult sounds to reconstruct or pronounce, but they are somewhat complex in their articulation, and often change in interesting ways in Indo-European languages. A match like what and Latin quod is straightforward (as long as you know about Grimm’s Law, at least), but it’s not unusual for other things to happen: sometimes the labial element takes over more completely, as in Greek po- from PIE *kʷo-, while other times it is lost entirely, as in Sanskrit ka-, from the same source. This ‘delabialization’ is very widespread in the Indo-Iranic, Balto-Slavic, and Armenian groups of Indo-European, a point which will become important shortly.
This is still relatively straightforward, so let’s get to the difficult bit. Let’s, once again, take a word that begins with h- in Old English: lean, which comes from Old English hlin-ian. You should know the drill by now: Old English h- should come from an earlier *k by Grimm’s Law. And at first glance, this prediction seems to be confirmed. Greek has a verb klín-ō ‘I lean’ (as usual, the - marks the boundary between the verbal base and a grammatical ending), and Latin also has a base clīn-ō (usually found in prefixed forms with more extended meanings, like dē-clīn-ō ‘turn aside’ and in-clīn-ō ‘cause to lean, bend’ – we’ve borrowed these as decline and incline). We can provisionally posit an old verbal base like *klin- to account for all of this. A closer comparison will tell us that the -n- is actually an old verbal suffix rather than a really core part of the word – we can see this in Greek words like klí-sis ‘bending, lying down’, which have no n in sight – so really we just have *kli-.

But what about Sanskrit? Since one of the basic sound changes in that language is PIE *l becoming r, we might expect something like ˣkri-. But actually we don’t find a form like this, which is why I’ve put a little ˣ in front of it. The actual cognate of lean in Sanskrit is... śri-. This ś stands for a fricative sound, a little bit like English sh (but more like sound in German ich). That’s not a k, nor even very k-like in any obvious way. As I mentioned, k is a velar sound, but ś is decidedly not: it’s formed by pressing a more forward part of the tongue up against the roof of the mouth, a part that’s called the hard palate – accordingly, we call ś a palatal sound. Why did Sanskrit end up with a palatal sound (and a hissing fricative rather than a momentary stop) where Greek and Latin (and certain other IE languages) have velar stops?
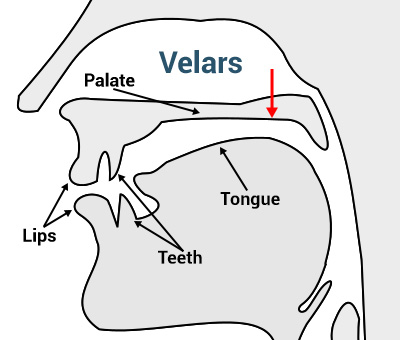
If we're being really nit-picky, the velum is also called the 'soft palate'. When linguists talk about the 'palate', they usually mean the 'hard palate'. Turns out that anatomists and linguists don't always have the same priorities in describing the mouth.
This weirdness isn’t limited to Sanskrit. Avestan, an old Iranic language closely related to Sanskrit, has forms like -srī-ta. Lithuanian, a Baltic language, gives us things like šlie-jù and šli-nù, where the š isn’t quite the same sound as in Sanskrit, but close to it (and definitely not a k of any sort!). Clearly whatever is happening, it goes beyond Sanskrit.
If we take a wider look, we’ll find that this sort of pattern is very widespread, going well beyond the cognates of lean. For many, many words, we find a k-type sound in Greek or Latin, but a palatal and/or sibilant element in languages like Sanskrit. The same thing also goes for Latin g, which often matches to the Sanskrit palatal stop j (phonetically [ɟ]).
To explain this, Indo-Europeanists usually make a distinction between the ‘plain’ velars like *k and a set of ‘palatal velars’ (aka ‘palato-velars’) which can be notated as *ḱ, basically with the k-ness of Greek and the acute accent mark of Sanskrit ś. (Other people use different headgear: *k̑, *g̑, or *k̂, *ĝ. The difference is just one of notation.) So now we have three sets of velars for PIE: plain *k, ‘labialized’ *kʷ, and ‘palatalized’ *ḱ. The interesting thing is what happens to these sounds later on.
There’s one big group of languages (mostly more westerly languages, including what would become English) where *k and *ḱ both tend to turn into *k, but *kʷ usually keeps its labial aspect in the earliest languages. We’ve already seen that this is the case for Greek and Latin, and also for Germanic, if we factor in Grimm’s Law. The Celtic branch (including Irish, Scottish Gaelic, Welsh, Breton, and dead Continental languages like Gaulish) also works like this. We call these centum languages, after the Latin word for ‘hundred’, which shows the change of *ḱ to Latin c (note that c was always ‘hard’, /k/, in Classical Latin).
 Centum languages in blue, satem in red.
Centum languages in blue, satem in red.
This map is a bit of an anachronistic mishmash, but it gives a decent general picture.
Another big groups of languages includes some of the languages I’ve mentioned already: Sanskrit and Avestan (and indeed all of the large Indo-Iranic group, including languages from modern Kurdish to Bengali), along with Lithuanian and the rest of the Balto-Slavic family (Baltic being a small group, now just Latvian and Lithuanian; Slavic a large group encompassing Russian, Polish, Bulgarian, and many other languages). To this second group we can probably add in the Armenian language of the Caucasus, which forms its own branch of the Indo-European linguistic tree. These languages all have two things in common. Firstly, *ḱ usually ends up as some sort of palatal and/or sibilant sound. Secondly, the labio-velars like *kʷ lose their labialization, and become plain k. I’ve mentioned both of these things separately, but it’s worth emphasizing that in all of these branches, the two changes go hand in hand – an intriguing correlation. We call these languages satem languages, from satəm, the Avestan word for ‘hundred’, an example of *ḱ becoming s in that language.
The Indo-European family has ten major branches. So far, I’ve mentioned seven of them. Greek (the Hellenic branch), Italic (including Latin), Celtic, and Germanic are all centum languages. Indo-Iranic, Balto-Slavic, and (probably) Armenian are all satem. What about the other three branches? One of them is Tocharian, an extinct family consisting of two languages once spoken in the oases of eastern Central Asia. The languages as attested show some pretty dramatic mergers of all velar-type sounds, but in its prehistoric development, pre-Tocharian was probably a centum language – the most striking thing about it is its geography, since Tocharian is found far to the east, while most other centum languages are in the west.
 The Taklamakan desert.
The Taklamakan desert.
The Tocharian languages were once spoken in oases and settlements around this region.
The other two branches are more interesting. One of these, Anatolian, is among the earliest recorded Indo-European branches, with Hittite and Luwian (along with the small corpus of Palaic) attested already in the second millennium BC. The last branch, Albanian, is among the most recently recorded of all Indo-European branches, with a written tradition extending back only to the late Middle Ages (that’s a few hundred years, but still pretty recent by IE standards). But both of them are remarkable for – possibly! – being neither centum nor satem, but keeping the three types of velars distinct.
Actually the evidence is pretty messy. Hittite, the prestige language of the Hittite Empire of ancient Anatolia, is the best attested of the Anatolian languages, and it looks like a normal centum language: *ḱ and *k both show up as k, while *kʷ shows up as kw (more or less – transliterating from Hittite’s cuneiform script involves some complications that I can’t go into here). But there’s evidence from the related Luwian language that *ḱ and *k had not merged, meaning that Proto-Anatolian still had three kinds of velars. This evidence is sometimes a little hard to interpret, because many of the consonants involved were undergoing various further changes, but most specialists in Luwian now think this argument holds up.
 A hieroglyphic inscription in a late form of Luwian (from the city-state of Karkamiš, dating to the 900s BC).
A hieroglyphic inscription in a late form of Luwian (from the city-state of Karkamiš, dating to the 900s BC).
Image from Payne 2010, Hieroglyphic Luwian, pp. 59-64.
The situation in Albanian is similar. This language is attested so very late that most of the original PIE sounds have undergone significant changes, and on top of that, we have to always double check that we’re dealing with words that actually came directly from PIE: Albanian has borrowed many words over the course of its history, including quite a number from Latin at a fairly early date. This means that not every Indo-European-looking word in Albanian actually comes directly from PIE by purely Albanian developments. Here’s one possible set of examples from Albanian might show the sounds *ḱ-, *k-, and *kʷ- each developing differently (and, incidentally, give a taste for Albanian’s complex sound changes):
*ḱēns- > thom ‘I say’ (PIE *ḱ seems to usually become th, pronounced as in English)
*kih₁- > qoj ‘wake, rouse, lift’
*kʷel- > sjell ‘bring, fetch, turn’
If these and similar reconstructions are roughly right, then Albanian, like Luwian, is neither a centum nor a satem language, and the presence of three different kinds of velars in PIE would be confirmed. (There’s also some evidence that Armenian may not be ‘fully’ satem, and could also preserve some traces of the *k versus *ḱ distinction.)
 Albania. Albanian has two major dialects, wonderfully named Gheg and Tosk.
Albania. Albanian has two major dialects, wonderfully named Gheg and Tosk.
So we have three types of velars for PIE, but how were they actually pronounced? This is actually a very difficult question. The labio-velars are pretty easy: they probably really were just labialized velars, so that *kʷ would phonetically be written the same way, [kʷ]. Remember that the italicized forms are conventional notations, and the ones in square brackets are phonetic indications of the (hypothesized) actual pronunciation.
The other two ‘velars’ are more difficult. Taken at face value, the term ‘palatalized velar’ would imply a sound pronounced by cutting off the airflow at the very front part of the velum, close to where it meets the hard palate – the pronunciation of the first k in English kick is a little like this. Phonetically this would make *ḱ [kʲ], where the superscript ʲ indicates the palatal quality of the k. The ‘plain’ velar *k would then just be normal [k], as in macaw. Under this view, the centum languages removed the palatal quality from *[kʲ] to merge it with normal *[k]. The satem languages, by contrast, exaggerated the palatal element of *[kʲ], but removed the labial element from *[kʷ].
 The 'c' of macaw is a fairly neutrally positioned velar stop.
The 'c' of macaw is a fairly neutrally positioned velar stop.
There’s a problem with this scenario, though. Among the languages of the world, [k] is usually a more basic and common sound than [kʲ], and normally more words have [k] than [kʲ]. But in PIE, it’s the other way around. We reconstruct way more words with *ḱ than with ‘plain’ *k. To bring PIE more in line with how human languages normally work, some scholars have suggested that actually *ḱ was not palatal at all, but just normal [k] – that explains why it’s so common. The so-called ‘plain velar’ *k would, under this view, not be a true velar at all, but rather a uvular stop. The funny little round tab hanging down in the back of your mouth is the uvula, so a uvular stop cuts off the airflow of speech there for a moment. It’s still pronounced in the back of the mouth, like a velar, but just a little further back. The voiceless uvular stop is notated as [q] in the IPA (this is based on Arabic convention; English q(u) is not uvular at all). If this proposal is right, then the traditional notation that Indo-Europeanists have used for generations is not accurate phonetically, and the real situation would be this:
*ḱ = [k]
*k = [q]
*kʷ = [kʷ]
If we go with this approach, then the centum languages merged *[k] and *[q] as [k], but kept [kʷ] distinct. This would be pretty understandable: [k] and [q] are distinct sounds, but still kind of similar. It’s not that huge of a deal for them to merge together.
 Tweety Bird standing next to Sylvester's uvula.
Tweety Bird standing next to Sylvester's uvula.
For their part, the satem languages would have turned all (or most) instances of *[k] into palatals, *[c], and then changed both *[q] and *[kʷ] to plain [k]. These might look like more radical changes, but they actually aren’t – some Mayan languages in Central America, for instance, experienced a very similar change of velar *k to palatalized *c, and uvular *q to velar *k (Proto-Mayan had no labio-velars). The change of *[kʷ] to [k] is something that we reconstruct no matter what.
 Drawing of the inscription on the Leyden Plaque, a belt plate inscribed with images and glyphs in the pre-Columbian Mayab script. The Classical Mayan language(s) of these inscriptions show the change of old *k to č and old *q to k.
Drawing of the inscription on the Leyden Plaque, a belt plate inscribed with images and glyphs in the pre-Columbian Mayab script. The Classical Mayan language(s) of these inscriptions show the change of old *k to č and old *q to k.
Image from Victoria Bricker 2008, 'Mayan', in The Ancient Languages of Asia and the Americas (ed. Woodard), p. 169.
I personally tend to find the second option, the ‘uvular theory’, pretty believable, but it’s hard to be really sure about this sort of thing. Remember that we’re reconstructing a prehistoric language here – often we can reconstruct the broad outlines of things very confidently, but the finer phonetic details can be more elusive.
This has been a very long post, so just to recap: the ‘velar’ sounds of PIE (including the centum-satem split) are an important part of the phonology of this earliest stage of English. We have not just one k-type sound, but three: a so-called plain velar *k (possibly actually a uvular stop), a so-called palato-velar *ḱ (possibly actually just a normal velar), and a labio-velar *kʷ (probably really a labio-velar). These sounds do a bunch of different things in the various Indo-European languages, but if pay attention to the details of sound changes, even unlikely looking pairs such as lean and Sanskrit śri-, or queen and the first part of ban-shee, can turn out to be regular developments of one or another of these various ‘velar’ sounds.

Further Reading
Virtually every discussion of Indo-European has to touch on the centum-satem issue, so there a lot of places you can read more about this. A good textbook in general is James Clackson’s Indo-European Linguistics: An Introduction (2007). I think this makes for an excellent companion to the Fortson book I mentioned last time: Fortson gives a very wide-ranging survey of Indo-European topics, while Clackson gives a more focused critical discussion of a number of key issues.
If you want to look more into the tangled evidence of Luwian and Albanian, you’ll need to dive into more specialized scholarship. Craig Melchert – a leading scholar of the Anatolian family – has an important paper from 2012 reviewing the Luwian evidence (and the earlier scholarship on the subject, including revising some details from his own influential 1987 article). I’ve taken the Albanian examples in this post from Ranko Matasović’s Grammatical Sketch of Albanian for Students of Indo-European. I’m by no means an expert in Albanian, but it’s an interesting language to look at – I decided to spend a little time on it because I think one of the attractions of looking at the Indo-European stage is getting a taste for some of English’s more far-flung and linguistically different relatives. At least I enjoy this sort of thing – my apologies to anyone who doesn’t like getting bombarded with random Albanian without warning.
There are more controversies about these than I’ve had the space to address. One view that’s been popular at certain times is that PIE really only had two types of velars (or even just one): you can check out one argument along these lines in Winfred Lehmann’s older book (1952) on Proto-Indo-European Phonology. Melchert, in the article linked to above, defends the mainstream three-velar reconstruction, as do many others, but does grant that in an earlier stage of ‘pre-Proto-Indo-European’ the distinction between *k and *ḱ might not have yet existed.
One thing that’s sometimes raised in this debate are doublets in some satem languages – especially Balto-Slavic – where words that we reconstruct with ‘palato-velars’ show variable palatalization. An example is the word *h₂aḱ-mon- ‘stone’, which in Sanskrit (the ancient satem language par excellence) is aś-man-, with the normal ś from *ḱ. But in Lithuanian, we find both akmuõ (in the standard language) and the more expected ašmuõ (in certain dialects). Things like this complicate the whole centum-satem problem further.
The idea that the PIE ‘plain velars’ were actually uvulars (and the ‘palato-velars’ were just velars) is argued at length by Martin Kümmel in his 2007 book Konsonantenwandel (‘Consonantal Change’). I generally try to only recommend works in English in these ‘further reading’ sections, but an absolutely enormous amount of research on the whole history of English (down right through Middle English) has been in German, and it’s really not possible to avoid it.
The Mayan sound changes that might provide a typological parallel for the Indo-European ‘uvular theory’ are discussed by Terrance Kaufman and William Norman in their 1984 piece ‘An Outline of Proto-Cholan Phonology, Morphology and Vocabulary’ (in an edited volume; the relevant bit is on pages 85-89). I'm even less familiar with Mayan linguistics than Albanian, but I do think it’s good (and certainly at least fun) to take a look at how things work beyond the specific history of English or even Indo-European. After all, it’s just one language family among hundreds on this planet, and it’s good to check how ‘normal’ our reconstructions are from a broader perspective. This question of ‘typology’ in reconstruction is something I’ll return to, since it plays a big role in a couple of other controversies about early sound changes.
