
Today I’m going to talk about the word bear. Not as in the large, honey-loving mammals, but the verb to bear, as in the Second Amendment to the US Constitution. This word is, as it happens, one of the most widespread verbal bases in the Indo-European family, and leads us into a discussion of the last set of Proto-Indo-European consonants that I’m going to talk about in this series.
 Not this kind of bear.
Not this kind of bear.
If we look at the cognates of bear, we find a certain number also beginning with b-. Old Irish (a Celtic language) has bir-t ‘carried’, and Old Chruch Slavonic (a Slavic language) has ber-ǫ ‘I carry’. Both of these languages belong to branches that were (pre)historic neighbours of Germanic, but b- forms are found further afield as well: Albanian gives us bie, and Avestan barə-.
This should already make us a little suspicious. Normally Grimm’s law means that such nice matches between Germanic and the rest of Indo-European don’t occur: we’d expect plain voiced stops like *b, *d, *g, etc. to turn into voiceless stops: Germanic *p, *t, *k, etc. So it looks like there’s something a little unusual going on with these b = b equations.
 Main cognates of English bear
Main cognates of English bear
From Lexikon der indogermanischen Verben (Lexicon of the Indo-European Verbs)
Our suspicions are only increased when we look at the rest of the family. Latin has fer-ō ‘I carry’, with an f, while Ancient Greek has pʰer-ō – the pʰ represents an ‘aspirated’ p. (Later on, Greek [pʰ] would turn into [f], which is why words of Greek origin in English often have ph pronounced [f], but that’s at a rather later stage of the language and we can ignore it for now. Remember that square brackets are used to emphasize that we’re talking about phonetic notation, the pronunciation of a sound as represented in the International Phonetic Alphabet.)
Let’s pause for a moment to talk about aspiration, since this is a pretty important concept for today’s discussion. A basic voiceless stop, like [p] or [t], is pronounced by doing two main things at once: shutting off the air flow in the mouth (by closing the lips, for [p], or using the front of the tongue, for [t]), and holding the vocal folds open so that they don’t vibrate (this is voicelessness, allowing air to move through the folds without any added buzzing). Aspiration occurs when these two things don’t line up: the airflow is unstopped in the mouth and air can escape again, but the vocal folds take brief moment to get vibrating again. During this slight gap, the air is just hissing out without any voicing. When I say ‘slight’, I do mean it: often literally less than the blink of an eye. In most languages with aspiration, the gap between releasing the stop and starting voicing again is between 60 and 125 milliseconds, while an average eyeblink is said to be around 100-150 milliseconds. But short as aspiration is, aspiration can be a very salient feature, and Greek sharply distinguishes plain p and t (and k) from aspirated pʰ, tʰ, kʰ.
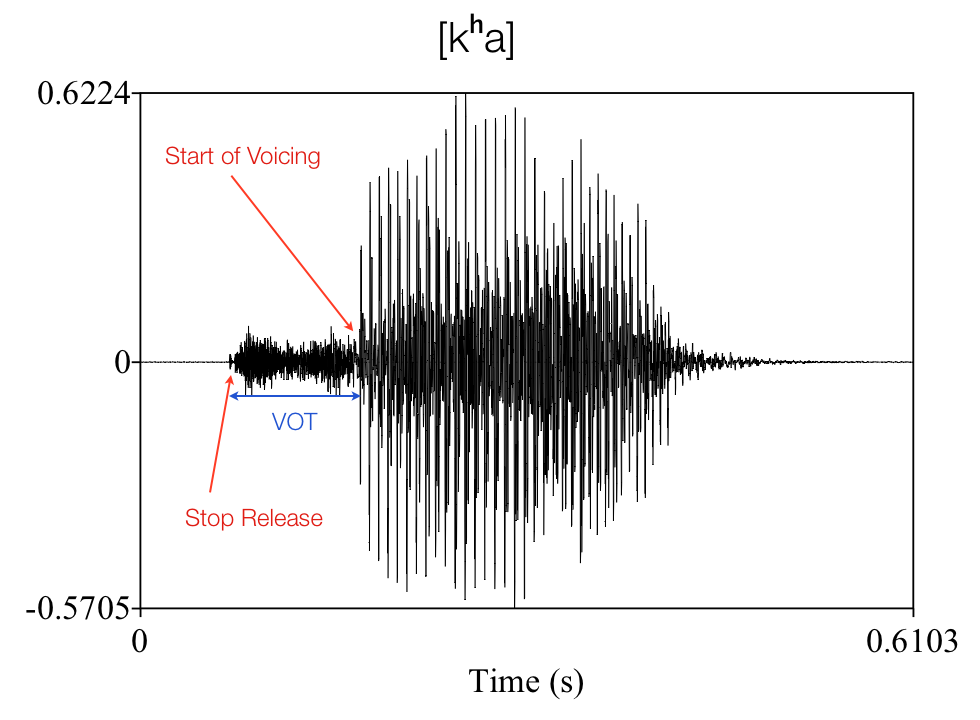 Simple spectrogram of a classic aspirated stop.
Simple spectrogram of a classic aspirated stop.
The gap between the 'stop release' and the 'start of voicing' (labelled VOT, Voice Onset Time) is what is perceived as aspiration.
(In English, plain p’s, etc., are actually often somewhat aspirated – it usually takes an English speaker around 60 milliseconds to get the vocal folds going again after releasing a p in a word like pessimist. Post-stress, in a word like happy, or after s, as in spy, this aspiration gap tends to be much shorter, closer to the ‘typical’ [p].)
Getting back to bear and its cognates, what does our old friend Sanskrit have? There the verb is bhár-ati, with the bh representing what’s often called a voiced aspirate. The concept is similar to voiceless aspiration. The lips are closed to stop the airflow for a moment, but after the lips are opened, the vocal folds don’t just sit still (as in normal aspiration), nor do they vibrate with ‘normal’ voicing (as for your standard [b]), but instead they vibrate ‘oddly’ or ‘breathily’ for a few milleseconds before returning to normal. In strict phonetic terms, this ‘odd’ vibration is called ‘breathy voice’, but phonologically it’s basically the voiced equivalent to aspiration, and I’ll stick to the traditional term ‘voiced aspirates’ for this type of sound. This sound gets notated various ways – bh, b̤, bʱ, and bʰ. I’ll go with the last, bʰ, to highlight its functional equivalence to plain aspiration, and as the most accurate notation from a phonological perspective.
Voiced aspirates can be a little hard to hear and pronounce if you’re not used to them. You can get a workable approximation by just saying a b and h together, like in the phrase lab horror. Here’s a video that’ll give you a general sense of what his sounds like (I do apologize for the obnoxious music – if anyone knows of a better online audio illustration of this sound, I’ll happily replace this).

So to get back to the cognates of bear, we have a situation where we find a b- in English and a few other branches of the family, an f- in Latin, a pʰ- in Greek, and bʰ- in Sanskrit (and many modern languages of the Indic family, such as Bengali). The traditional assumption is that all of these sounds go back to *bʰ in Proto-Indo-European. In Germanic (and Celtic, Balto-Slavic, etc.), the breathy-voice/aspiration element was lost, leaving b. In Greek, the voicing was lost, but the aspiration stayed, giving pʰ. It is not an uncommon thing for aspirated stops to turn into fricatives, and this happened in Latin, giving f (perhaps via a stage like *pʰ). In Sanskrit, there simply was no change, and bʰ stuck around.
Not everyone agrees with this reconstruction. There are two main objections. The less compelling one is that voiced aspirates are found only in the Indic branch, and shouldn’t be projected back into Proto-Indo-European. Even if this were true, this would not be a strong argument: it is perfectly possible for a sound in a proto-language to only survive in a small portion of its descendent languages (English w and th, [θ], are both relatively rare in the Germanic family, but are securely reconstructed for Proto-Germanic).
In any case, voiced aspirates are also known from another branch of Indo-European: Armenian. This language is spoken in a large number of dialects, historically centered in the southern Caucasus region, and now spoken globally by a number of diaspora communities who fled the Armenian genocide by Turkey.
 Amberd Fortress in Armenia.
Amberd Fortress in Armenia.
Research into Armenian form an Indo-European perspective is complicated by the presence of a very large number of early loanwords from Parthian, and Iranic language that exerted influence on Armenian during the first few centuries AD, when Armenia was under the control of the Parthian (Arsacid) Empire. This lexical influence was so enormous that it displaced much of the inherited Armenian vocabulary, leaving only a few hundred words which come directly from Proto-Indo-European into Armenian without being mediated through Iranic. Some of these inherited words are famous for showing some quite spectacular sound changes: a favourite textbook example is the word for ‘two’, where *dwō has become, entirely regularly, erku (stress on the final syllable). (This didn’t happen directly, of course, but in a long series of small steps that eventually really added up.)
,_Seleucia_mint.jpg) Coin depicting Vologases I (Walayš in Parthian), minted 51 or 52 AD.
Coin depicting Vologases I (Walayš in Parthian), minted 51 or 52 AD.
Vologases invaded Armenia and brought it into the Parthian Empire.
In Indo-European studies, Armenian is usually represented by Classical Armenian, which has a written tradition starting before 500 AD. In this variety, the cognate of bear is ber-em ‘I carry, bring’, with a plain b. This plain b is also found in some modern dialects, but others show a voiced aspirate instead, bʰ-. There is debate about how to best reconcile these dialectal differences, but one plausible and well-supported view is that this bʰ- was not some new innovation by certain dialects, but that Proto-Armenian had *bʰ (and *dʰ, etc.). Classical Armenian would then show a sound change, of *bʰ- > b-, which affected some (but not all) Armenian dialects. If so, then the Proto-Armenian cognate of bear would be *bʰer-, virtually unchanged from the traditional reconstruction of Proto-Indo-European *bʰer-, and showing the same voiced aspirate as Sanskrit bhar-.
 A 14th century Armenian manuscript.
A 14th century Armenian manuscript.
However, there is another objection to reconstructing *bʰ and the like for Proto-Indo-European, which comes from phonological typology. To get a sense of what this is all about, let’s back up over a hundred years, to Karl Brugmann (whose massive grammar of Indo-European I mentioned in the last post). The classical, Brugmann-style tradition of Proto-Indo-European reconstructed four kinds of stops: voiceless (like *t), voiced (*d), voiceless-and-aspirated (*tʰ), and voiced-and-aspirated (*dʰ). This was a fairly elegant kind of system, where two phonological features (voicing and aspiration) could combine in all the logically different ways to produce the four kinds of stops.
This changed after the discovery of the laryngeal consonants, which I discussed in the last post. People realized that what they had been reconstructing as single sounds like *pʰ and *tʰ were actually better reconstructed as sequences of a plain stop plus a laryngeal: *ph₂, *th₂, and so on. I don’t really have space to go into the evidence for this in detail, but it’s proven widely convincing, and since the 1950s most researchers have abandoned the set of voiceless aspirates altogether.
This is where the typological problem comes in. Current mainstream reconstructions posit three types of stop: *t, *d, and *dʰ. Phonologists usually regard voiceless stops like /t/ as the simplest and most basic kind of stop. Voiced stops like /d/ are seen as t’s with the feature of VOICING added on. Aspirated stops like /tʰ/ are seen as t’s plus the feature ASPIRATION (you’ll also find this feature called spread glottis, which can be shortened to just spread; peanut butter is not meant). Normally, we’d expect these thing to build up in complexity: it’s weird to have stops like /bʰ/ and /dʰ/, which have both voicing and aspiration, without having stops like /pʰ/ and /tʰ/, with aspiration only. This weirdness is not just a matter of theory: there are a few languages with systems that kind-of, sort-of correspond to what we now reconstruct for Proto-Indo-European, but none are exact matches, and even partial matches are very rare. Sanskrit and dialectal Armenian both have voiceless aspirates, like tʰ, to accompany their dʰ’s.
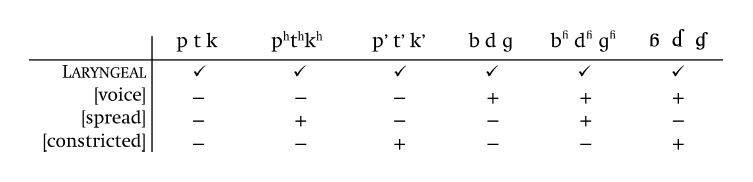 A chart of how different features combine (ignore the top row). A + means that feature is present for that class of sound, a - means it is absent.
A chart of how different features combine (ignore the top row). A + means that feature is present for that class of sound, a - means it is absent.
Voice is vibration of the vocal folds.
Spread is 'spread glottis', and refers to aspiration.
Constricted is 'constricted glottis', and refers to glottalization of consonants.
Going from left to right, the names for the stop types are: plain (voiceless), aspirated, ejective, voiced, breathy-voiced (aka voiced-aspirated), and implosive.
This typological issue remains a problem for the reconstruction of Proto-Indo-European. Many people have tried to reinterpret the whole system, arguing that all the ‘voiced aspirated’ stops (*bʰ, *dʰ, etc.) were actually just plain voiced stops (/b/, /d/, etc.). This, however, requires a further reinterpretation, since the stops that are traditionally reconstructed as plain voiced (like *d), now need to be interpreted as something else. The full history of such alternative proposals (usually broadly lumped together as ‘glottalic theories’) is too much to get into in this post, but I’ll put in a few pointers in the ‘further reading’ section for anyone who wants to follow up on this rather contentious area.
For now, the mainstream view seems to be that the reconstruction of voiceless stops (*p, *t, etc.), voiced stops (*b, *d, etc. – though *b is extremely rare), and voiced aspirated stops (*bʰ, *dʰ, etc.) really does have typological problems, but that none of the alternatives proposed so far is convincing enough to adopt instead. Even those who are committed to an alternative model tend to still use symbols like *bʰ, even if they think it was pronounced very differently, in order to stay cross-compatible with everyone else in the field. So people will usually write the Proto-Indo-European forebear of bear as *bʰéreti, whether they think this was */bʰéreti/ or */béreti/, or perhaps something else entirely.

In any case, leaving the controversies aside for the moment, the standard reconstruction of Proto-Indo-European still works with these ‘voiced aspirates’, and they occur at all the positions of articulation as the other stops do. The full set is: *bʰ, *dʰ, *ǵʰ, *gʰ, and *gʷʰ. These can be among the weirder looking Indo-European consonants, but they’re really nothing to be afraid of, and we’ll see plenty more of them in etymologies as we start looking at how Proto-Indo-European developed into Germanic, and then English.
We’ve now reconstructed all of the Proto-Indo-European consonants. If we arrange them in a nice chart (to show how sounds are built from features, like voicing and aspiration), we get something like this:
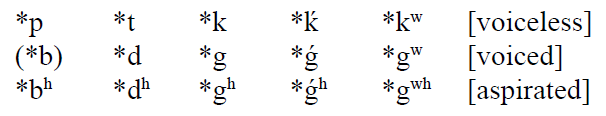
Further Reading
This post has covered quite a bit of ground, including at least one major area of controversy, so this is going to be a much longer section than usual.
To start off with, you can find a general overview of the Indo-European voiced aspirates in any of the various textbooks that I’ve mentioned so far in this series.
I’ve tried to simplify the explanation of things like aspiration and glottalization, to avoid getting bogged down in unnecessary phonetic details. The main feature of aspiration that I focused on, the gap between releasing the stop and starting up the voicing again, is known as Voice Onset Time, or VOT. The classic discussion of these things from a phonological perspective is Linda Lombardi’s 1994 Laryngeal Features and Laryngeal Neutralization (‘laryngeal’ here its proper sense of ‘having to do with the larynx’, and not referring to the three Indo-European laryngeals – this terminology can be confusing). A good introduction to how these sorts of sounds are actually pronounced phonetically in different languages is Peter Ladefoged’s Vowels and Consonents (3rd edition, revised by Sandra Drisner, from 2012). A more comprehensive and detailed survey is Ladefoged & Ian Maddieson’s 1996 book The Sounds of the World’s Languages.
The reinterpretation of pʰ, tʰ, etc. as *ph₂, *th₂, etc. is made by Windred Lehmann in his 1952 book, which I cited a couple of posts back.
The question of whether the breathy voiced stops in Armenian go back to Proto-Armenian or not is a tricky one. There are two earlier articles (predating the main ‘glottalic theory’ arguments) that I think make pretty decent cases for the antiquity of breathy voice in Armenian: Hans Vogt 1958, Les occlusives d’arménien, Norks Tidsskritf for Sprogvidenskap 18, pages 143-161; and E. Benveniste 1959, Sur la phonétique et la syntaxe de l’arménien classique, Bulletin de la société linguistique de Paris 54, pages 46-68. Somewhat more recently, Andrew Garrett’s 1998 article also makes a strong case for reconstructing breathy voice in Proto-Armenian based on the effects of the sound change known as Adjarian’s law.
More generally, I'm not aware of any really good introductory grammars of Classical Armenian. There is a free online series as part of the University of Texas's Early Indo-European Online series. For reference grammars, there's a rather old but still good one by the eminent French Indo-Europeanist Antoine Meillet, and a somewhat more recent (1975) book in English by Robert Godel. Birgit Anette Olsen's book on the Armenian noun has some very good, detailed, and up-to-date discussions of a lot of issues in Armenian historical grammar.
‘Glottalic Theories’
The ‘glottalic theory’ in its classic form goes back to 1973, with two major papers appearing that year, both apparently coming up with the idea independently: one by Paul Hopper, and one by Tamaz V. Gamkrelidze & Vyacheslav V. Ivanov (I don’t have a link to this: the title is ‘Sprachtypologie und die Rekonstruktion der gemeinindogermanischen Verschlüsse’, and it appeared in the journal Phonetica, volume 27, pages 150-156; you can find an abstract here). Gamkrelidze & Ivanov’s arguments are given more more fully in their very interesting (though often rather idiosyncratic) book Indo-European and the Indo-Europeans (translated from Russian in 1995 by Johanna Nichols); the relevant sections begin on page 45.
These early arguments all suggested that the traditional *d-stops were not plain voiced, but actually ejective consonants, /t’/, etc. Ejectives are stops that are, basically, pronounced with a simultaneous glottal stop. I would call this early form of ‘glottalic theory’ more precisely an ejective model.
A variant of this theory was developed by the ‘Leiden School’ of Indo-European linguistics (for a good introductory textbook written within this framework, see Comparative Indo-European Linguistics by Robert S.P. Beekes, revised by Michiel de Vaan). Alwin Kloekhorst gives a fairly full set of references for the ‘Leiden’ approach to Indo-European stops in his 2016 article on the subject, especially pages 232-235. This approach holds that in Proto-Indo-European as such, the *d-style stops were ‘pre-glottalized’, phonetically [ˀt]. Phonologically, these would still probably count as a type of ejective. In all the non-Anatolian branches of Indo-European, these stops are supposed to have changed from [ˀt] to voiced [ˀd] (in phonological terms, I would say this amounts to a change from ejective to a kind of implosive stop, though I don’t believe anyone working in this tradition has ever characterized the change this way).
This kind of approach, which I might call an ejective-to-implosive model, is in part meant to overcome one of the major difficulties of the classic glottaic theory (the ejective model). This is, how do you get from an ejective stop, like */t’/ (whether this is phonetically *[tˀ] or *[ˀt], or variably both) to the voiced stops that we actually find in most branches of Indo-European (this sound usually turns up as d). The ejective-to-implosive model says that the voicing change was a common innovation, part of the shift from ejectives (which are quintessentially voiceless) to implosives (which are phonetically complex, but phonologically usually voiced).
A third kind of glottalic approach picks up on the idea of implosives, and proposes that these go all the way back to Proto-Indo-European proper, without necessarily having ever come from ejectives at all: a strict implosive model. One of the most interesting and prominent examples of this approach is the so-called Cao Bang Theory, which is a way of using the implosive model to get to the traditional, typologically odd reconstruction, drawing a parallel with a set of sound changes from the Cao Bang language, a Tai language spoken in Vietnam. This theory is explained very clearly in a powerpoint by Michael Weiss, with a rather entertaining opening image. A version of this theory has also been elaborated in an important paper by Martin Kümmel. Since this proposal would actually derive the traditional system from an earlier system with implosives, it might be better termed an implosive-to-nonglottalic model.
I’ve discussed some of my own thoughts on the whole issue, along with quite a few further references, in a separate blog post. I was responding in part to a recent article by Alan Bomhard, linked to in that post, which gives a more detailed overview of the whole history of the debate, with plenty of further references. For the purposes of this series, I will simply adopt the more traditional, non-glottalic reconstruction of PIE stops, though I personally find the implosive (to non-glottalic) model of Weiss and Kümmel to be an attractive solution to some of the typological difficulties of the traditional view. I am not that concerned about whether the *d-type stops were (once?) glottalic in some way, but I am fairly strongly persuaded that the *dʰ-type stops really were voiced aspirates in at least ‘Common Indo-European’.
