
The last few posts have rather lingered on Proto-Indo-European, but it’s about time to start thinking about how this changed and developed into such a massive family including languages now as diverse as Icelandic, Kurdish, Portuguese, and Armenian. In a sense, this is picking up the story from back in post 2, on how Indo-European grew out of earlier languages in Eurasia (perhaps including ‘Nostratic’, if that existed), by looking at how the family went on to change and develop and eventually split up.
Linguists model these changes uses tree charts, and these linguistic trees are the main theme for the day. (If you’re wondering why this is nominally a post on groom, don’t worry – I will get there, eventually!) A fairly typical tree for Indo-European is pretty non-committal, with ten major branches radiating off, as if the proto-language exploded all of a sudden into a bunch of different sub-varieties:

One type of Indo-European 'family tree'.
(From Garrett 1999, 'A New Model of Indo-European Subgrouping and Dispersal')
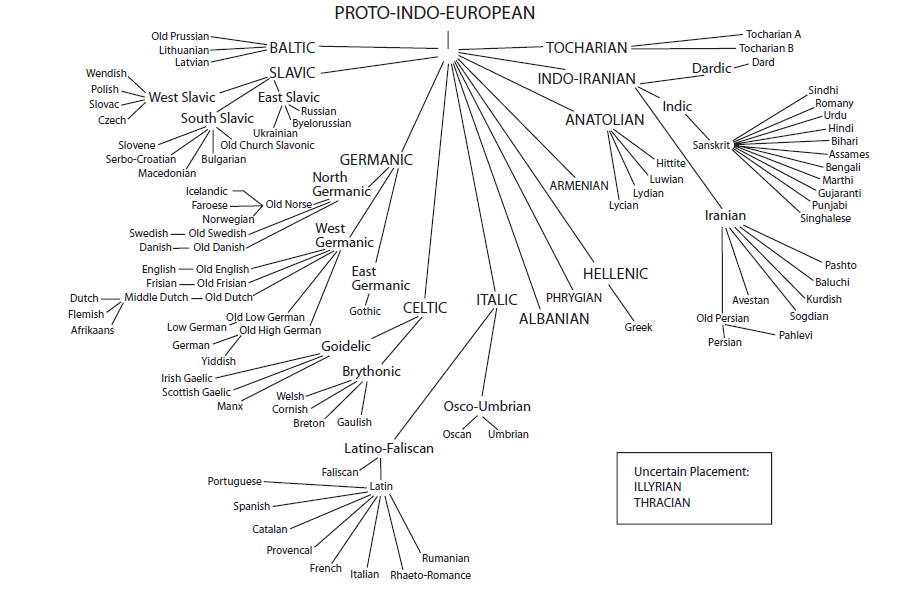
We’ve met quite a few of these ten ‘branches’ in passing already, and a number of the branches contain languages that are probably at least vaguely familiar to most of you already. The Italic branch, for instance, contains Latin and all the later Romance languages, while Greek has traditionally played a prominent role in European intellectual history. The Indo-Iranic (or Indo-Iranian) branch supplies the ‘Indo’ part of Indo-European, and includes Sanskrit (a classical language of India) as well as a host of later languages from Persian to Bengali. Other branches are perhaps a little more obscure: even if you’ve heard of Albanian and Armenian, you may not necessarily be aware that each of these constitutes a distinct branch within Indo-European. Two branches are fully extinct, with no modern languages at all, namely Anatolian and Tocharian. Celtic and Balto-Slavic both include languages spoken in Europe. So far, that makes nine of the major branches of the family: the tenth is, of course, Germanic, to which English belongs.
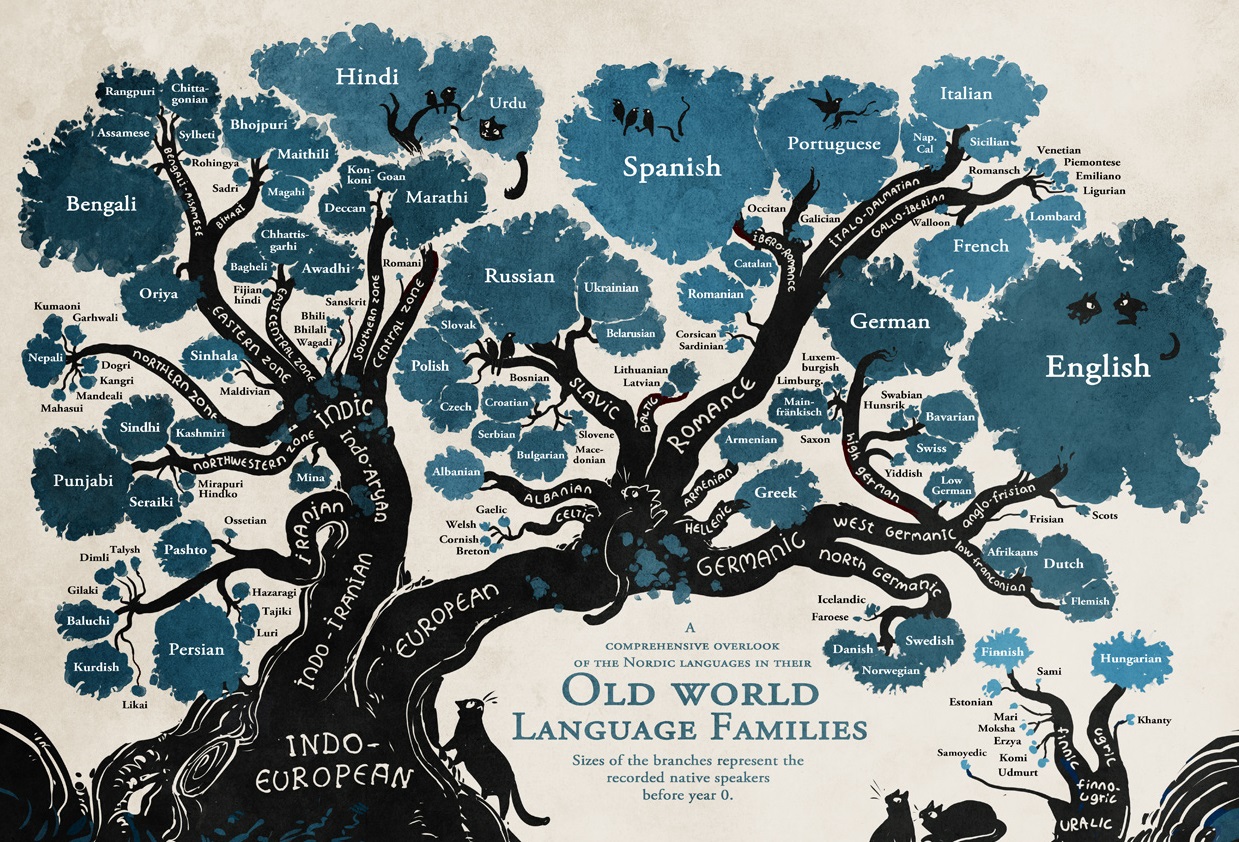 A rather prettier and, well, more tree-like tree.
A rather prettier and, well, more tree-like tree.
(Note that this is a tree for modern languages only, so branches like Tocharian and Anatolian are not present, and older languages like Latin are also absent.)
(This comes from a very good webcomic Stand Still, Stay Silent.)
So, did these ten branches really ‘explode’ apart, going from a single proto-language to ten distinct branches with a snap of the linguistic fingers? It’s possible to imagine some sort of historical (or, I suppose I should say, prehistorical) events that led to something like this, with Proto-Indo-European very quickly disintegrating into a large number of discrete speech communities, which each more or less went their own way.
Another take on the 'explosion' tree, this time with selected Indo-European languages included.
(From Anthony 2007, p. 12)
But while there might be explosive aspects to the splitting up of Indo-European, it probably wasn’t a matter of totally immediate or clean breaks. While imaginable on paper, things are usually messier in reality, and in any case, we have at least some linguistic evidence that some aspects of how Indo-European diverged were somewhat more drawn out. Changes like the development of the feminine grammatical gender, or the centum-satem developments, have the look of things that at least started in a messier dialect continuum, where varieties of Common Indo-European were starting to go their own ways into increasingly distinct dialects, but hadn’t yet totally lost contact with one another.
Exactly how we should model this kind of slower breakup isn’t clear, but one popular response has been to draw more sophisticated trees, ones that show early interrelationships between dialects more precisely. We can maybe think of this as looking at the linguistic ‘explosion’ in slow motion, to see just how Common Indo-European breaks up into the many later language groups that we know from later records. Here’s one fairly well-known attempt:
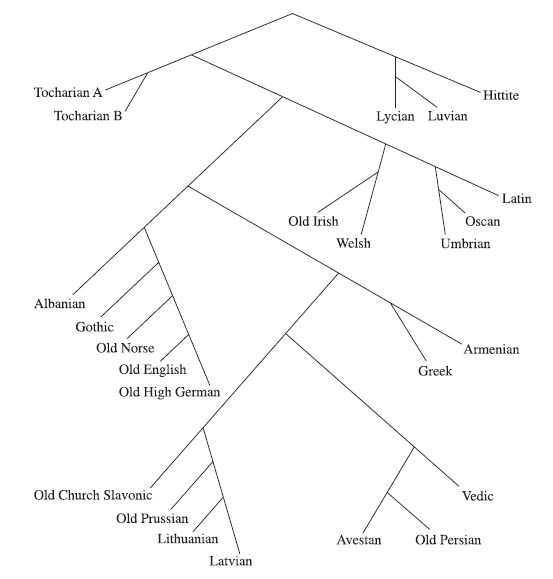
A less explody tree (every split is modelled as going into two and only two branches).
(From Ringe, Warnow, & Taylor 2002, p. 87.)
This particular tree shows Anatolian – that’s the group that includes Hittite – as the first ‘branch’ off the ‘tree’. (This graphic doesn't actually mark Proto-Indo-European, but it's meant to be the point at the top.) This is a pretty popular view, and most (though by no means all) Indo-Europeanists now accept this idea, and specifically hold that Anatolian did not just split off first, but did so a fair while before the other dialects began to break up. If this is right, it explains a bunch of things: Anatolian does not, as mentioned last time, have a feminine gender in its nouns, so maybe the whole group branched off before the feminine gender became standard within Common Indo-European.
Another concrete example is the old Indo-European word for ‘earth’. In many Indo-European languages, the word seems to begin with a consonant cluster: we find Greek kʰtʰṓn (reflected in the rather high-fallootin’ English adjective chthonic), Vedic Sanskrit kṣam-, and Tocharian tkaṃ, among others. These could point to a Proto-Indo-European form like *dʰǵʰom-. But Hittite has something slightly different, a basic form tēkan, with a clear vowel between the two consonants. It’s now pretty well accepted that the Hittite form is more archaic than the others. Probably the word was something like *dʰégʰom in the nominative case (the ‘subject’ case), and underwent ablaut to something like *dʰgʰmés in the genitive (the form that the English ’s possessive ultimately comes from). Hittite keeps this alternation pretty well, since tēkan is the nominative form, and taknas is the genitive (the a may not even be a real vowel, but just something inserted graphically due to the awkwardness of Hittite’s cuneiform script when writing consonat clusters). The other languages may have simplified the ablaut by getting rid of the variation between *dʰeǵʰ- and *dʰǵʰ-, and just using the latter form everywhere. If all this is more or less right, it would be another, pretty clear example of Hittite heading off in one direction, and the rest of Indo-European in another.
 A Chthonian (a being from the Lovecraftian mythology).
A Chthonian (a being from the Lovecraftian mythology).
There are a bunch of other features that people try to explain in a similar way, and some people even argue that we should think of a ‘Proto-Indo-Anatolian’ that early on split into two very divergent sub-branches: the Anatolian family and the rest of Common Indo-European. This in turn then ‘exploded’ off into the nine remaining branches, possibly at a much later date. There are a lot of very controversial details that I’m papering over, but the basic idea that Anatolian left early, and didn’t take part in some otherwise widespread innovations, is a fairly mainstream view these days.
But what about the rest of the ‘explosion’? How did that work? If you compare this tree to other trees that different researchers have proposed, you’ll find a whole lot of disagreements. For instance, this tree puts Albanian and the Germanic languages pretty close together, which is a bit surprising.
There are a few reasons for why researchers disagree so much. One possibility is that aside from the split with Anatolian maybe being a bit earlier, the ‘explosion’ of Common Indo-European into various sub-groups took place relatively quickly. There are also issues with methodology, since the lion’s share of evidence (all of it in some studies) comes from vocabulary – and in particular, cases where a new word has replaced an older one. This kind of evidence is useful because it’s more abundant and can often be more clearly interpreted than sound changes or grammatical innovations, but it’s also problematic in its own way: vocabulary shifts can cross dialectal boundaries relatively easily, so if two dialects remained in (or came back into) contact they might share quite a bit of new vocabulary even if they were already linguistically divergent in other respects. Of course, vocabulary replacement doesn’t always spread across dialect lines in this way, so it’s not useless evidence. It just makes things a bit messier, and is an additional reason to take trees of this type with a grain (or a handful) of salt.
 The data used for making trees is all just 'words, words, words'.
The data used for making trees is all just 'words, words, words'.
For the history of English, the branch we’re most interested in is Germanic. Actually in the Ringe, Warnow, & Taylor tree up above, Germanic posed a bit of a problem, and didn't fit in well (see pages 86-92), and they go on to produce a second tree with Germanic simply omitted. Many other trees have tended to place Germanic closer to Balto-Slavic, Italic, and Celtic. This would make a certain amount of geographical sense, since these four groups are all later found in Europe, and in more recent millennia continue to interact with one another extensively. For this very early period, just after the break-up of Common Indo-European, things are inevitably more speculative, but we might reasonably think of a ‘European dialect area’ of early Indo-European languages.
These ‘European’ languages didn’t necessarily form a single branch on a linguistic tree, though. None of the evidence used to build these kinds of trees really justifies such a strong claim. All we can say on the current evidence is that Germanic, Balto-Slavic, Celtic, and Italic probably continued to share some similar types of changes, even as each branch also steadily accumulated more and more unique innovations to set it apart from all the others. Hence labels like ‘dialect area’ instead of ‘branch’.
For a concrete example of what might have been going on with the ‘European dialect area’, we can pick up on that the old word for earth, *dʰéǵʰom. We’ve already seen that Anatolian may have split off first, leaving the rest of Common Indo-European to adopt forms with an initial cluster, *dʰǵʰom-. At a later date still, a few branches within Indo-European took this word for ‘earth’, *dʰǵʰom-, and added a suffix to it (along with a bit of ablaut, just to make things fun) to make a new derivative: *dʰǵʰm-on- ‘one who lives on the earth, earthling, human’ (this is in contrast to the gods, who as celestial beings live in the sky). The initial consonant cluster *dʰǵʰm- was now a real beast, and the word was simplified to *ǵʰm-on-. The most familiar word that comes from this is Latin homō, as in Homo Sapiens. In Germanic, the word used to be very common, and Old English had a word guman- that comes from *ǵʰm-on-. We’ve very nearly lost the word since then, except for a compound word that was, in Old English, brȳd-guma ‘bride-man’, which has turned up (with an irregularly added r) as bridegroom today.
 A random bridegroom.
A random bridegroom.
There are differences of opinion, but it’s reasonable to see this word *ǵʰmon- as an example of what was going on in the ‘European dialects’. The base word for ‘earth’ was Common Indo-European, but the derivative ‘human’ doesn’t seem to be quite as old. It’s found only in Italic, Baltic (Old Lithuanian has a cognate žmuõ), and Germanic. These three groups never formed a single ‘branch’ on the Indo-European tree, but they probably were spoken in the same general areas not long after the breakup of Common Indo-European. New words that were coined, including derivatives like this, could easily spread around between dialects, even as they were becoming linguistically more and more divergent in other ways.
Despite my use of the term ‘European dialect continuum’, I’m really talking, so far, about strictly linguistic relations. It’s not necessarily the case that these ‘European’ languages were actually yet in Europe when some of these ‘European’ features developed. In fact, the whole question of pinning down Proto-Indo-European geographically is a major controversy and entire area of study in its own right. But it’s an important question, and in the next posts I’ll tackle the extremely knotty problem of just where and when Proto-Indo-European (or at least Common Indo-European) might have been spoken, and how, when, and why the Indo-European languages eventually came to be spoken across such a large area of ancient Eurasia.
Further Reading
The practice of using trees to represent linguistic relationships goes way back, to August Schleicher in what was one of the first great overviews of Indo-European: his 1861 Compendium der vergleichenden Grammatik der indogermanischen Sprachen [Compendium of the Comparative Grammar of the Indo-European Languages]. After reviewing the Indo-European branches known in his day, Schleicher presents this tree on p. 7:
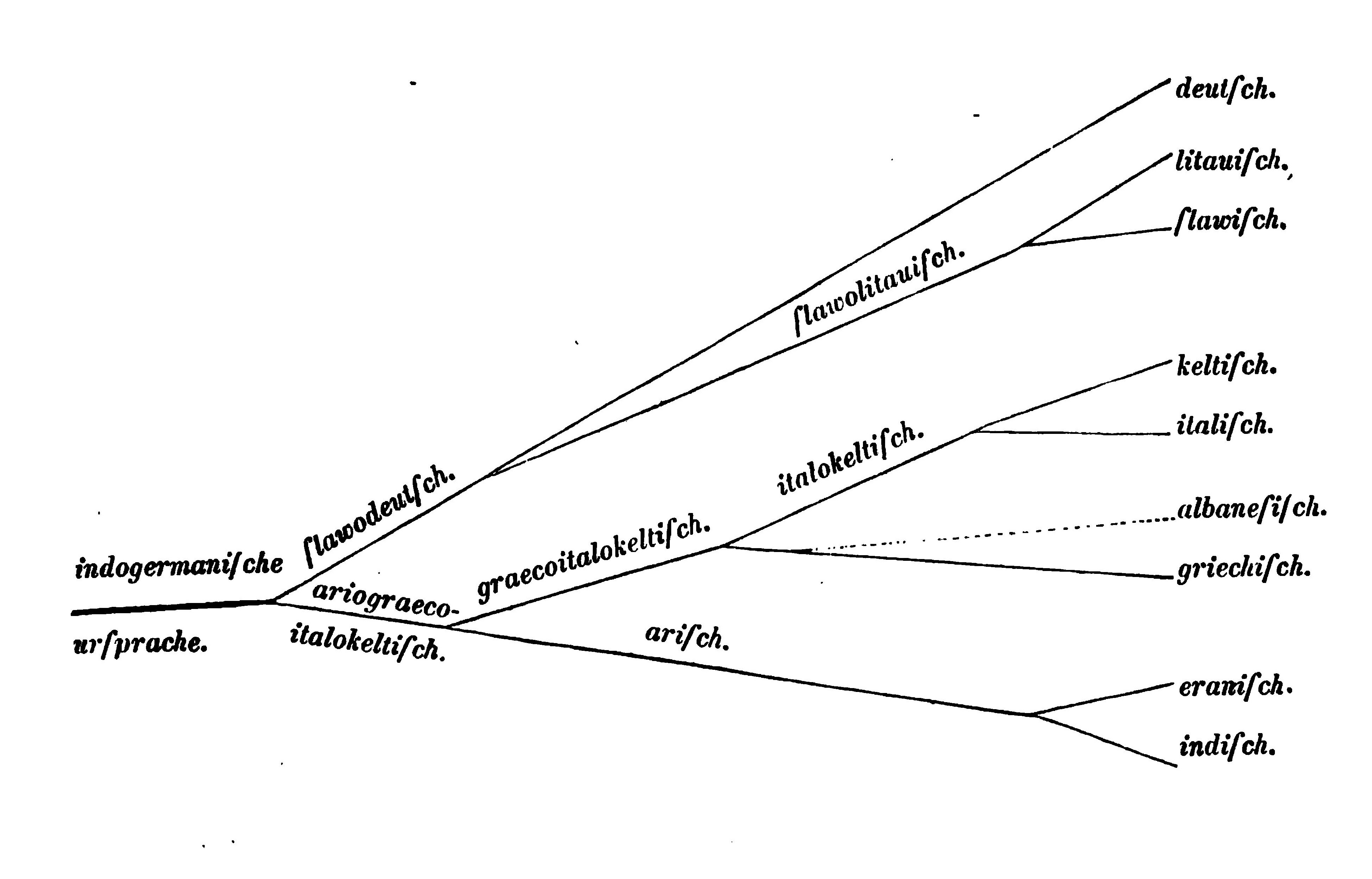
Since then, there has been considerable work on trees in linguistics. The general theory was sharpened up considerably by Henry Hoenigswald in his 1960 book Language Change and Linguistic Reconstruction, and has been elaborated still further by Mark Hale, Historical Linguistics: Theory and Method (2007).
For Indo-European specifically, the paper by Ringe, Taylor, and Warnow has been very influential, and is part of a new methodological approach that has now become standard: the use of what’s called computational phylogenetics to produce trees. Phylogenetics is a fancy word for how things emerge from other things – in this case, how the Indo-European languages developed from Proto-Indo-European, and what intermediate sub-groups there were along the way. I should emphasize that in linguistics, ‘phylogenetic trees’ have nothing to do with DNA or genetics in a biological sense. Such techniques were first used for linguistic purposes on a different language family – Austronesian, by Gray & Jordan 2000 – but have now been repeatedly applied to Indo-European. Influential studies include Gray & Atkinson 2003 (p. 437), Bouckaert et al. 2012 (p. 959) and Chang, Cathcart, Hall, & Garrett 2015 (pp. 199-200) – though many of these studies are much more interested in inferring the overall date of Proto-Indo-European than in determining the internal positioning of most branches. There is also a project afoot to produce a higher-quality database of vocabulary material as the basis for future phylogenetic projects, which might well produce somewhat more reliable results once completed (though it’s still fundamentally oriented around the lexicon, which is a drawback nearly all studies of this type share): https://www.shh.mpg.de/438157/cobldatabase
Many of these computational trees, drawing on vocabulary evidence, place Tocharian as also being fairly divergent – not quite as much so as Anatolian, but still splitting off from Common Indo-European fairly early on. This lexical evidence is challenged by Melanie Malzahn in a recent paper, and in general the idea that Tocharian is ‘more divergent’ is, while a common assumption, probably not something we should take for granted.
The practice of tree-building is often contrasted with the ‘wave model’, which is (in most representations) a competing way of indicating linguistic history. The idea is that linguistic innovations (say, a sound change or a new word) spread around like waves in a linguistic pool, starting from some point and spreading out from there. Different waves of innovations may partly overlap, creating complex patterns of divergence over time.
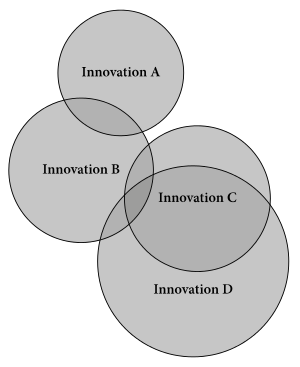 The 'wave model' of linguistic innovations.
The 'wave model' of linguistic innovations.
Just imagine it's a pond or something and you're a some kind of god tossing in little pebbly linguistic innovations.
This isn’t really at odds with the tree approach, though the two schemes are often presented as somehow incompatible. Trees model linguistic relationships as represented by the very first reconstructible divergence – two branches of a tree may continue to share innovations (be splashed by the same wave), but remain phylogenetically distinct. This is obvious when we’re talking long-separated languages, like when English borrowed words from French in the Middle Ages, but there’s no qualitative difference in cases where dialects have only just begun to diverge. Most waves model innovations in partly diverged dialect continua, and so just don’t represent the same kinds of things that trees usually get at. Both are important parts of language history, and neither gives a complete picture of things (that is, in fact, rather the point: to give a boiled down representation so that certain important relationships can be clearly communicated). There are other models still out there for representing linguistic relationships of various types, each with its own use in context.
On groom specifically, I’ve assumed that its derivation took place just within the ‘European dialect continuum’, based mainly on the fact that *ǵʰmon- isn’t found in that many branches, and not at all outside of ones later spoken in Europe (just Germanic, with guman- and groom, Italic with Latin homō, and Baltic with early Lithuanian žmuõ). Not everyone agrees, though – Norbert Oettinger (2003, p. 184) thinks that *ǵʰmon- already existed in Proto-Indo-European proper, because it forms an opposing pair with the word *deiwo- ‘deity, skyling, celestial being’. But if this formed such a natural pair, why was it lost in so many branches of Indo-European? As far as I can see, there’s no reason why *deiwo- couldn’t be much earlier (it’s found in many more branches, including Indo-Iranic), with *ǵʰmon- being a later, European derivative created as a natural, but not inevitable, response to it. Still, questions of this sort are a matter of judging imperfect evidence – so I’ll stick with groom as probably being an example of a ‘European dialect’ word, but leave the door open for it just maybe actually being an older formation.
 For some reason, the movie Prometheus decided to represent Indo-European as the language of primordial skylings who founded life on earth or something.
For some reason, the movie Prometheus decided to represent Indo-European as the language of primordial skylings who founded life on earth or something.
Shockingly, this is not very linguistically accurate, but it does lead to a scene with some sort-of Proto-Indo-European on-screen, which doesn't happen every day.
As a (too) brief final note: without getting too far into the details, I'll just say to anyone who's used to seeing the word as *(dʰ)ǵʰm̥mon- or *(dʰ)ǵʰm̥on-, with a syllabic *m̥ in there, that I don't believe we need a Lindeman's variant for the nominative, just analogy from the obligue.

{kind=link}